【Rails】ルーティング情報をフィルタリングするコマンド作成
最初に
rails routesコマンドといって、ルーティングの一覧をだすコマンドがある。
(※rake routesではない)
しかし、ActiveStorage周りのルーティングで、めちゃくちゃ幅をとったりして、とても読みにくい。
特定のキーワードでフィルタリングした上で、幅を絞ると見やすくなるのでは、と思い実装した。
探せば同じ目的の機能がありそうだけど、実装も簡単だし、ちゃっちゃと実装した。 lsコマンドのlオプション付きのを実装したことがあるから簡単だった。
コード
以下のコードをrakeファイルに追記する。
使い方は、コードの先頭に書いたとおり。
# rake routes F=devise # rake routes V=GET F=devise # rake routes V1=PATCH V2=PUT # rake routes F1=devise F2=users # rake routes F1=devise OP=AND F2=users desc 'Print out all defined routes with filtering' task :routes do routes = `rails routes` routes = routes.split("\n") routes.shift routes = routes.select{ _1.index(ENV["V"]&.upcase || '') && _1.index(ENV["V1"]&.upcase || '') && _1.index(ENV["V2"]&.upcase || '') } if ENV["OP"]&.start_with?("A") || ENV["AND"] || ENV["A"] routes = routes.select{ _1.index(ENV["F"]) } if ENV["F"] routes = routes.select{ _1.index(ENV["F1"]) } if ENV["F1"] routes = routes.select{ _1.index(ENV["F2"]) } if ENV["F2"] else r1 = routes.select{ ENV["F"] and _1.index(ENV["F"]) } r2 = routes.select{ ENV["F1"] and _1.index(ENV["F1"]) } r3 = routes.select{ ENV["F2"] and _1.index(ENV["F2"]) } routes = r1 | r2 | r3 end routes.map! do |route| route.gsub!("(.:format)", "") row = route.split row.unshift("") if row.size == 3 row end prefixes, verbs, uris, actions = routes.transpose max_prefix_size = prefixes.map(&:size).max max_verb_size = verbs.map(&:size).max max_uri_size = uris.map(&:size).max max_action_size = actions.map(&:size).max puts routes.map!{ |prefix, verb, uri, action| "#{prefix.rjust max_prefix_size} #{verb.ljust max_verb_size} #{uri.ljust max_uri_size} #{action.ljust max_action_size}" } end
サッと書いたり修正したりしたので、いつもよりバグってるかもしれない。
コード解説
routesコマンド
task :routes do
この部分で、routesサブコマンドで呼び出すものを定義している。
実際にはRakefileにあり、rake routesで呼び出す。
ルーティング一覧を取得する
routes = `rails routes` routes = routes.split("\n") routes.shift
Railsから直接取れるのだろうが、Railsの機能を調べるのが面倒そうだったので、
`rails routes`で直接コマンドを叩いて1回取得して加工することにした。
これをやると、コマンドを2回叩いてることになるので、その分遅くなっているかもしれない。
そのあと、改行"\n"で分割して行単位の配列にして、routes.shiftでヘッダー部分を取り除いている。
Verbで絞る
routes = routes.select{
_1.index(ENV["V"]&.upcase || '') &&
_1.index(ENV["V1"]&.upcase || '') &&
_1.index(ENV["V2"]&.upcase || '')
}
Rakeファイルでの引数の取り方がわからなかったので、コマンドの呼び出し時に環境変数を指定してもらって、 環境変数をコマンドライン引数代わりにしている。
V=GETとすると、GETのルーティングのみに絞れる。
V1=PATCH V2=PUTとすると、PATCHかPUTのルーティングのみに絞れる。
upcaseをつけて、V=getのように小文字でも絞れるようにした。
AND検索
if ENV["OP"]&.start_with?("A") || ENV["AND"] || ENV["A"]
OP=ANDやAND=trueと書くと、AND検索になる。
rake routes F1=users F2=posts OP=AND
3列のものを4列に揃える
rails routesで取れる情報は、path/urlヘルパーメソッドがあったりなかったりする。
いったん行データをsplitで配列して、サイズが3(つまり、3列)なら、空文字列を入れる形で4列にする。
routes.map! do |route| route.gsub!("(.:format)", "") row = route.split row.unshift("") if row.size == 3 row end
あと、"(.:format)"の文字列は、あっても価値が低く思うので、取っ払うことにした。
transposeして、列幅を求めて出力
全部のデータを4列にしたのもあり、transposeでデータを転置して、列ごとに取り出せる。
列ごとに取り出して、列ごとの文字列の最大値を求めることで、必要な列幅がわかる。
で、最後にrjustやljustを使って、右や左に寄せたりして、出力して終わり。
ActiveStorageを試し、image_tagのエラー文などについて少し調べた
最初に
Qiita: ActiveStorageを使ってお手軽にファイルアップロードを試す
この記事で失敗するという話を見て、久しくActiveStorageを使ってなかったので試してみた。
結論からいうと、画像なしでユーザー登録すると、画像が見つからずview側でエラーが起こる。
ただ、このエラー文がわかりにくく(image_tagによるもの)、それについて少し調べた。
あと、解決方法のメソッドattached?, present?, blank?について気になった点があったので、少し調べた。
Qiita記事と異なった些細な点について、いくつか
Qiita: ActiveStorageを使ってお手軽にファイルアップロードを試す
記事通りにやるだけだが、いくつか記事と異なる点があった。
バージョン違い
mini_magick -> image_processing
また、Rails 6からmini_magickではなくimage_processingをデフォルトで使うことになっているらしく、
Gemfileにはimage_processingが書かれていて、その代わりに記事通りにmini_magickを使った。
今回の実験では、mini_magickで特に問題はなかった。
rails db:create
rails db:migrateの前に1回rails db:createを挟む必要があった。
sqlight3では不要ぽいが、PostgreSQLでは必要。
Viewの画面でのエラー
<% @users.each do |user| %> <li> <p><%= user.name %></p> <%= image_tag user.avatar %> </li> <% end %>
の<%= image_tag user.avatar %>で、ユーザーがavatar画像を持たないとエラーになる。
画像を持っていれば、別にエラーにはならない。
image_tag内で起こっているエラーだが、これがわかりにくかった。
なお、このエラーはS3を使う前でも確かめられる。
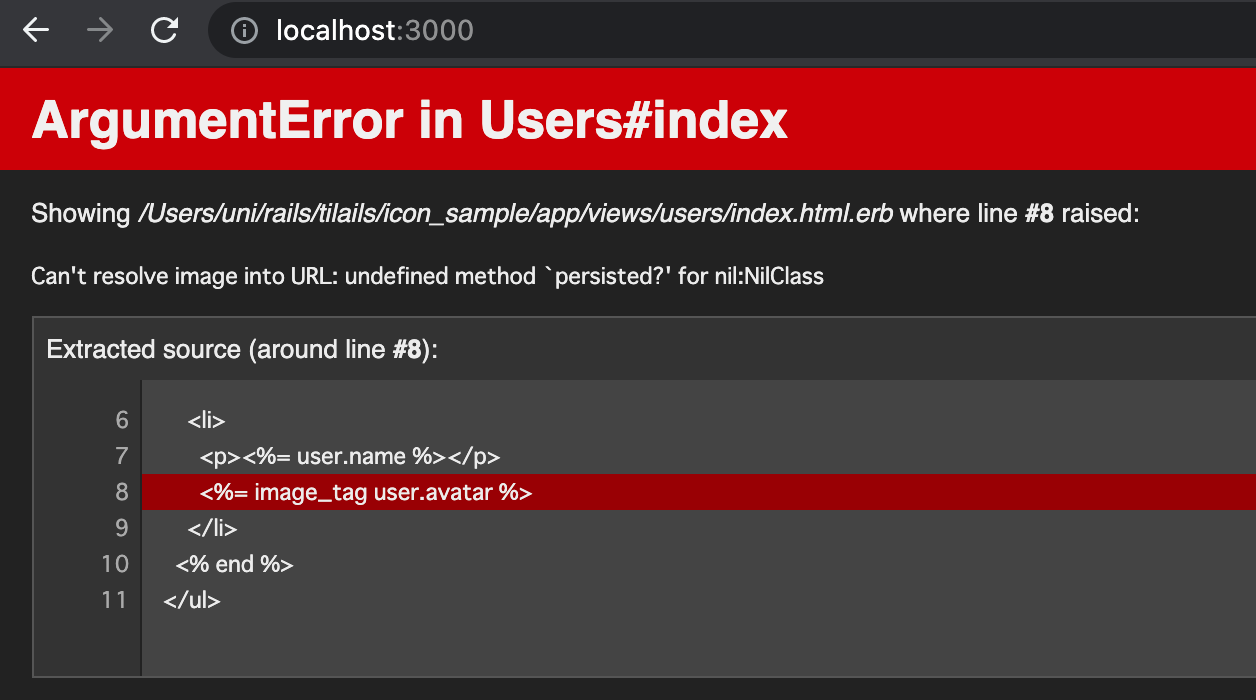 文字をコピペすると、以下。
文字をコピペすると、以下。
ArgumentError in Users#index Can't resolve image into URL: undefined method `persisted?' for nil:NilClass
また、あとで少し書くが、user.avatarはActiveStorage::Attached::Oneクラスのインスタンスで、
画像がなくても直接nilになっているわけではないようだ。画像のないActiveStorage::Attached::Oneクラスのインスタンスが、
image_tagヘルパーメソッドに渡されるとエラーになる。
ArgumentErrorが起こっているらしいが、エラーの説明文の中にundefined methodの文字が見える。
undefined methodならNoMethodErrorなのではないかと最初は思った。
どうも調べてみると、Railsのimage_tagヘルパーメソッド内部でnil.persisted?が呼ばれNoMethodErrorが起こり、
image(画像)をURL(文字列)に変換できなかったため、
そういうエラーが起きるような引数があったということでArgumentErrorとなっているらしい。
nil.persisted?が呼ばれたという情報はRails内部のことで、出来ればもっと隠蔽して、もっとわかりやすいエラーにして欲しいなと思った。
image_tag(1)
image_tagに1を与えてみると、同じ「Can't resolve image into URL: 」というエラー説明文が表示された。
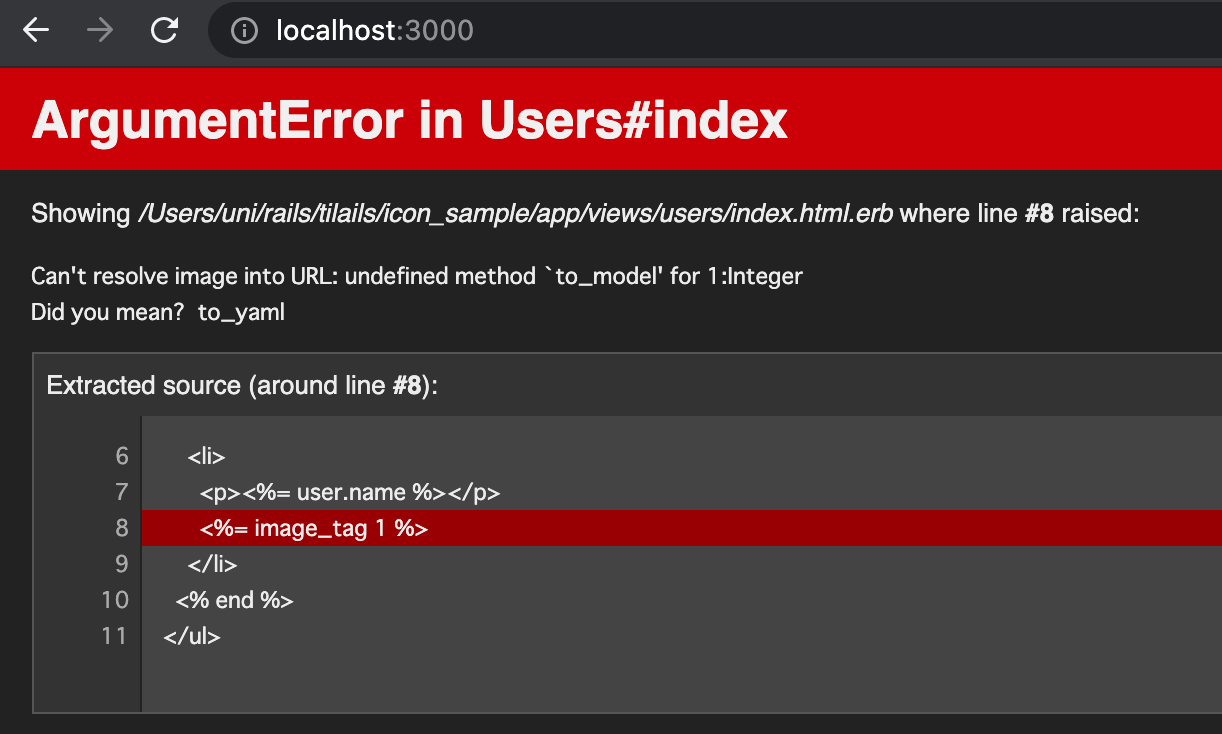
ArgumentError in Users#index Can't resolve image into URL: undefined method `to_model' for 1:Integer Did you mean? to_yaml
image_tag(nil)
nilを与えると、次のようなエラーになった。nilは、場所となる画像URLを生成できないから、エラーになるらしい。
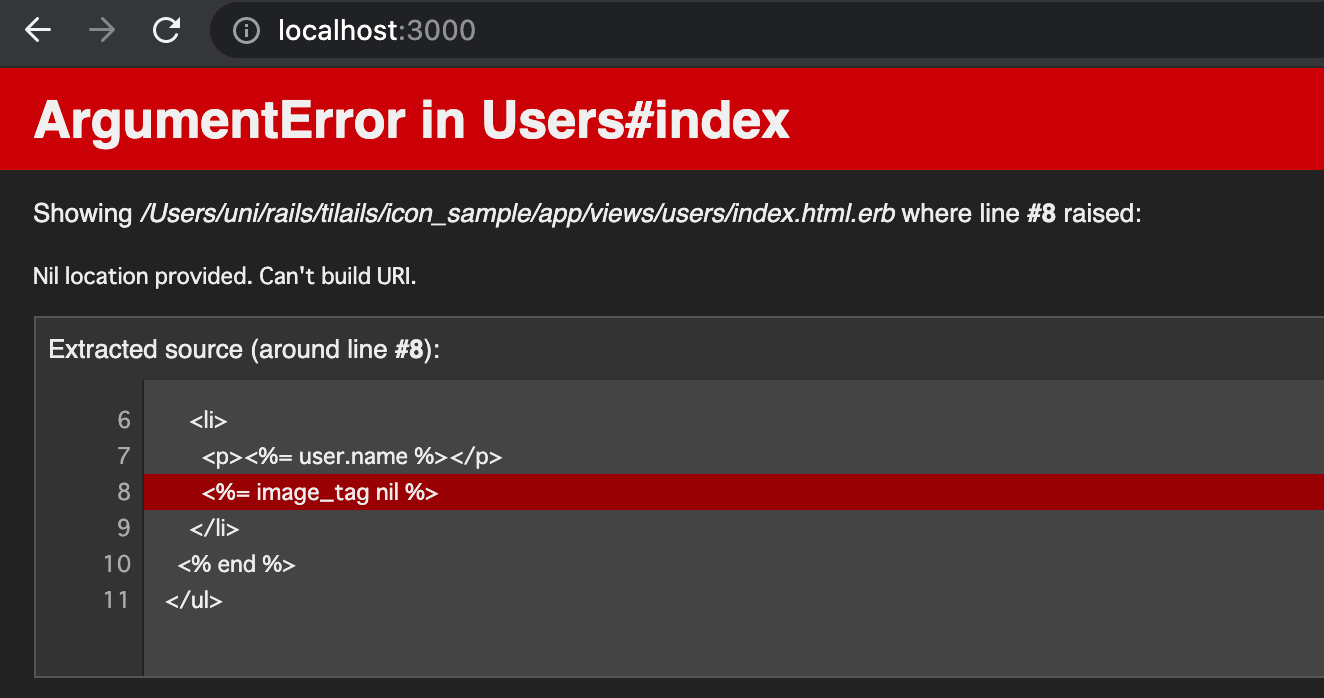
ArgumentError in Users#index Nil location provided. Can't build URI.
image_tag(適当な文字列)
適当な文字列を与えると、次のようなエラーとなった。
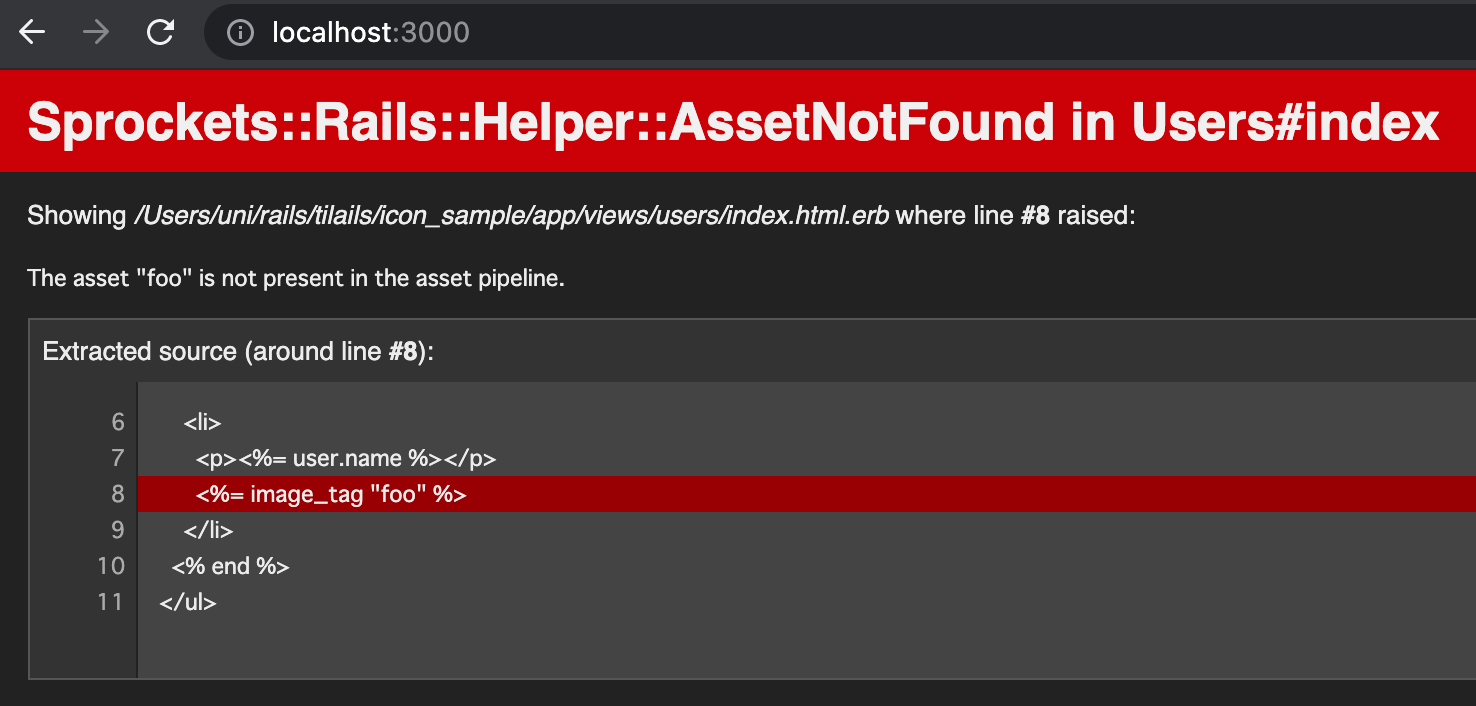
Sprockets::Rails::Helper::AssetNotFound in Users#index The asset "foo" is not present in the asset pipeline.
fooという場所が存在しないから、エラーになるらしい。 引数の種類としては変ではないせいか、ArgumentErrorにはならなかった。
エラー回避方法
<%= image_tag user.avatar %>を以下のどれかに変更して、
画像が存在するときにだけ、image_tagにuser.avatarを渡してあげれば解決する。
<%= image_tag user.avatar if user.avatar.present? %> <%= image_tag user.avatar if user.avatar.attached? %> <%= image_tag user.avatar unless user.avatar.blank? %>
いずれも画像を持つかどうかを調べるメソッドだが、
この3つのpresent?, attached?, blank?の関係性について見ていく。
present?メソッドなどの詳細
ここでuser.avatarというのはActiveStorage::Attached::Oneクラスのインスタンスである。
メソッドの中身を紐解くと、present?とattached?は機能的に同じメソッドである。
present?は、ActiveSupportによるRails拡張のメソッドで、
Objectクラスに定義しているため、それを継承しているActiveStorage::Attached::Oneでも使えている。
present?は、内部で単にblank?メソッドを呼んで否定しているだけである。
def present? !blank? end
そして、blank?とattached?メソッドは、ActiveStorage::Attached::Oneに定義されている。
Rails API: ActiveStorage::Attached::Oneのドキュメントから確かめることができる。
def blank? !attached? end
ActiveStorage::Attached::One#blank?は、単にattached?を呼んで否定するように定義されている。
つまり、present?メソッドは、attached?の否定の否定なので、機能的には結局attached?と等しかった。
attached?の方がきっと僅かに速いだけなので、この2つはエイリアスと呼んでいいと思う。
最後に
Railsのエラー文はもっとわかりやすくなって欲しいなと思った。終わり。
【Ruby/Rails】LoadError: cannot load such file -- rexml/documentというエラーへの対処法と原因
最初に
RailsないしRubyを使っているときに、
LoadError: cannot load such file -- rexml/document
というようなエラーがでることがある。
これの対処法や原因について、簡単に書く。
対処法
エラー文は「rexml/documentが読み込めない」と言っている。
rexml/documentとは、rexmlというgemのサブライブラリと呼ぶべきものだ。
gem 'rexml'
この行をGemfileに追記しbundle installして、rexmlを使えるようにする。
原因
Ruby 3.0 で、rexml は、Default gemからBundled gemとなった。
Default gemもBundled gemも、Rubyをインストールしたときに一緒にインストールされるgemである。
しかし、前者は、Rubyコアチームで管理されアンイストールすることは出来ず、
後者は、Rubyコアチーム外で管理されアンイストールすることができる。
どうもこの区分が変わったことで、rexmlを使う場合は使うことを明示的に指定する必要があるようだ。
仮にこちらがrexmlを直接使う気がなくても、何らかのgemを使う際にそのgemがrexmlに依存していて、
間接的にrexmlを使う必要があって、失敗することがある。
むしろ、間接的に使って失敗することの方が多いだろう。
例えば、自分はRailsでrails test:allコマンドを実行するときに、失敗した。
本来なら1番rexmlに依存しているgem側のGemfileないしgemspecにrexmlを指定して欲しいところ。
自身のGemfileにrexmlを指定する以外にも、エラーが起きるgemにrexmlを指定するようにPRを送ってマージしてもらって、最新のgemを使うのが1番いい。
まぁ、PRを送ってもすぐマージされなかったりするので、結局自分のGemfileに書いておくのが1番手っ取り早い解決方法となるだろう。
参考
Standard Gems
冒頭にDefault gemsとBundled gemsの定義が書いてある。
letter_opener_web PR #106
letter_opener_webというgemはrexmlに依存している。
rexmlを明示的に指定するようPRがでているが、管理者の反応がまだない。
rails/rails Issue#41502 rails test fails with cannot load such file rexml/document
Railsでも、rexml/documentがロードできず、テストが落ちることが報告されている。
Rubyのテストカバレッジのためのgemのsimplecovが良かった。あと、Rubyのバグを直してもらった。
最初に
Rubyでテストカバレッジとしては、
Rubyコアにcoverageライブラリがあり、
Gemとしてはsimplecovというのが有名ぽいです。
simplecovを使ったら良かったという話とRubyのバグが見つかったことを書きます。
simplecovの使い方
インストール方法
GitHubの公式simplecov-ruby/simplecovにやり方は書いてますね。
Gemfileか*.gemspecファイルに、simplecovをインストールするように書く。
gem 'simplecov'
本番環境で使うものではないので、本番環境から除いてインストールにするとよさそうですね。
とりあえず使うことを目的として、ここでは1番シンプルなものを書きました。
自分のケースですと、Gemの開発でテストカバレッジを調べたかったので、以下のように書きました。
spec.add_development_dependency "simplecov"
Gemの開発者だけが使う場合は、このように書けばいいはず。
そして、bundle installコマンドを実行して、インストールします。
実際の使い方
GitHubの公式simplecov-ruby/simplecovに書かれていますが、 次に記述を追加します。
require 'simplecov' SimpleCov.start
このコードは、simplecovライブラリをロードして、SimpleCov.start(カバレッジ計測の開始)を実行してるだけです。
この記述を書く場所ですが、この記述を書いたあとにrequire_relativeなどで呼び出したファイルを計測してくれるので、次のように書きます。
require 'simplecov' SimpleCov.start require_relative 'convolution_test' require_relative 'crt_test' require_relative 'dsu_test'
これを書いたコードを実行してあげます。
そうすると、coverageディレクトリに色々とファイルが作られるのですが、
その中にindex.htmlがあり、これをブラウザで開いてあげます。
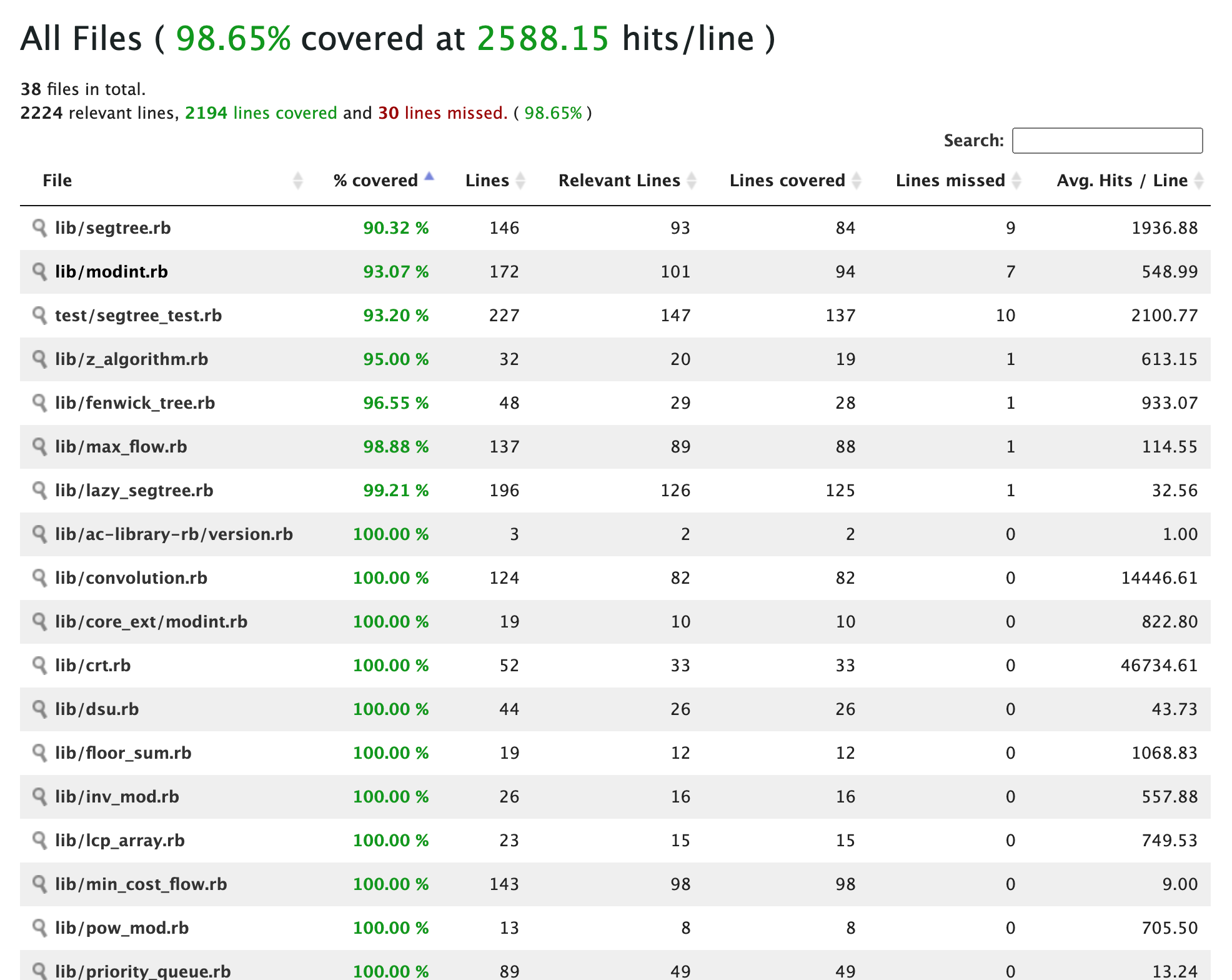
めっちゃ綺麗でわかりやすいです!!
% coverdが100%であれば全てのコードが実行されたことになり、
テストが網羅的に書かれていそうだなとわかります。
実際にファイルでどこの行が実行されたのか、何回実行されたのかまで見ることができます。
赤色のコードが実行されてないコードです。
こうすることで、テストできてないコードや実行されてないデッドコードがわかり便利です。
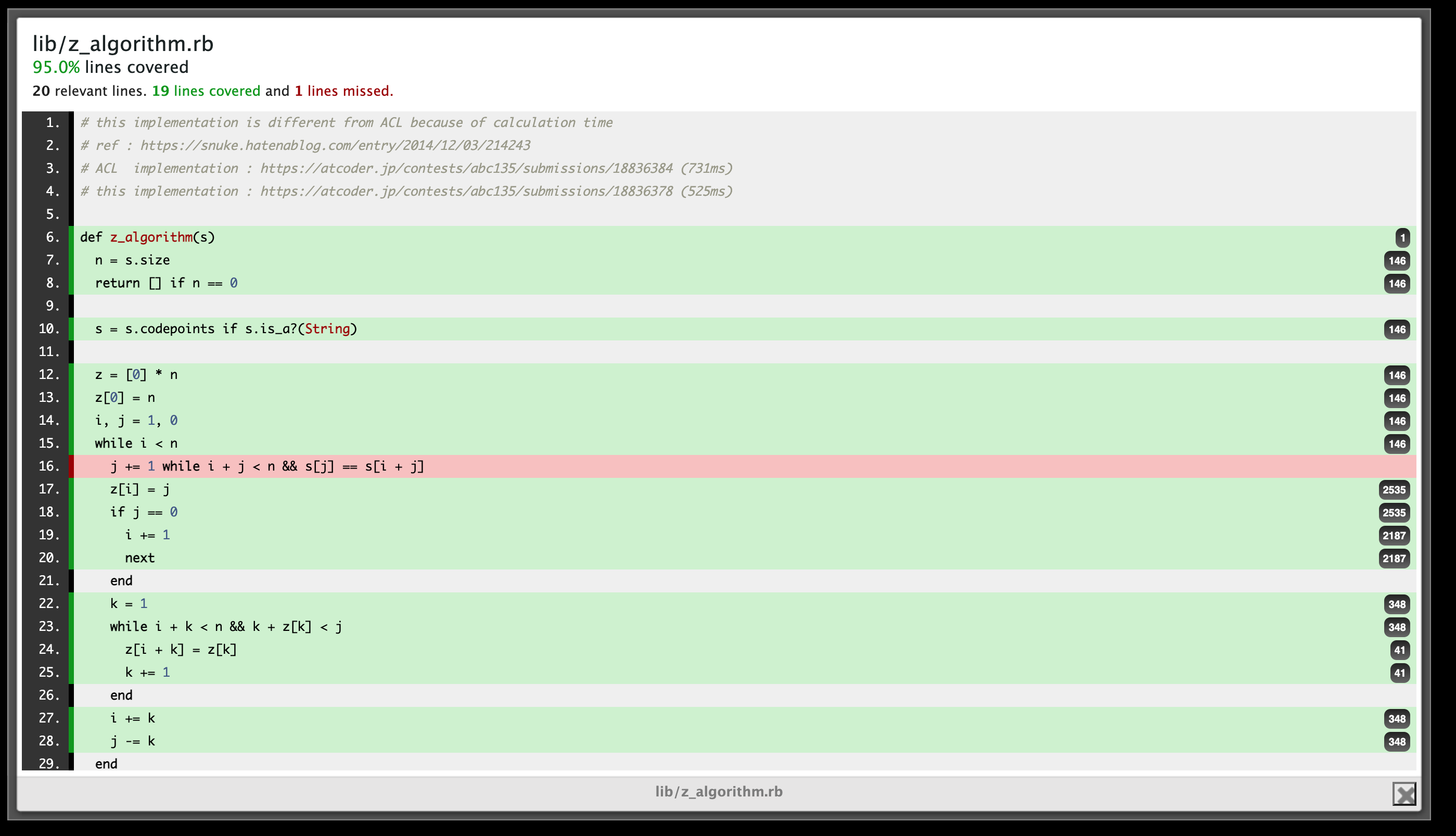
バグが見つかる
ところで、上の画像なのですが、赤色のコードを調べてみると明らかに実行されていました。
バグのようです。simplecovのバグかなと思い、Issueを見たのですが、それらしき報告はありませんでした。
Issueを立てようと思ったのですが、Rubyにも標準添付のcoverageがあって、そっちを試したらどうなるのだろうと思ったら同じ現象が起きました。
具体的にどのようなファイルで、バグがあるのかというと、次のようなwhileの中にwhileがあるケースの一部で、中のwhileがカウントされません。
n = 3 while n > 0 n -= 1 while n > 0 end
これをカバレッジ計測対象のwhile_in_while.rbとします。
このファイルに対して、次のように計測してみます。
require "coverage" Coverage.start load "while_in_while.rb" pp Coverage.result # {"while_in_while.rb"=>[1, 1, 0, nil]}
while_in_while.rbの3行目のn -= 1 while n > 0は実行されているはずなのに、実行された回数が0回になっています。
なお、4行目のendは実行されるべきものではないので、nilを返しています。
ここで:all指定で全モードで計測すると、:lines=>[1, 1, 1, nil]で中のwhile文が1回実行されているとなりました。
違う結果になって、バグか何かだろうと確信しました。
require "coverage" Coverage.start(:all) load "while_in_while.rb" pp Coverage.result # {"while_in_while.rb"=> # {:lines=>[1, 1, 1, nil], # :branches=> # {[:while, 0, 2, 0, 4, 3]=>{[:body, 1, 3, 2, 3, 20]=>1}, # [:while, 2, 3, 2, 3, 20]=>{[:body, 3, 3, 2, 3, 8]=>3}}, # :methods=>{}}}
気持ち的にはn -= 1が3回実行されているから3回でもありなのではと少し思いましたが、1回でも良さそうです。
とにかくモード指定しなかったときの行のカウント等が0回となっており、0回と1回以上とでは大違いです。
simplecovがRubyのcoverageライブラリを使っているから同じことが起きるのかなと思い、
Rubyコア側に報告することにしました。
報告したら、すぐ変更してもらえた
whileの中にwhileを書く機会のあるコードを書く人は少数派で、これに遭遇する人は少ないだろうなと思いつつも、
0と1は違うので報告することにしました。
報告したら、コミッターのmameさんにすぐ対応してもらえました。良かった。
最後に
テストカバレッジで100%になっていると気持ちがいいですし、とても安心です。
あと、Rubyリファレンスマニュアル(るりま)のcoverageの説明の情報が古かったのでPRをだしておきました。PRがたまっていて時間がかかりそうですが、そのうち対応されると思います。(1ヶ月後とかになるかも)
テストカバレッジの手法をあまり知らないので、知ってたら教えてくださると嬉しいです。
「こんなgemがあるよ」とか「こんなgemを使ってます」とか。
【Ruby】ABC202 こと エイシングプログラミングコンテスト2021の参加記(E問題まで)
AtCoderのABC202 こと エイシングプログラミングコンテスト2021に参加しました。
本番はD問題まで解けて、本記事ではE問題まで書いています。
A - Three Dice
サイコロの問題。
a = gets.to_s.split.map{ |e| e.to_i }
puts 21 - a.sum
いつものように入力はCrystalにすぐ変換できるように、to_sをつけたり、map{ |e| e.to_i }と書いている。
3個じゃなくて任意の複数個に対応できるようにするには次のようにする。
a = gets.to_s.split.map{ |e| e.to_i }
puts 7 * a.size - a.sum
1分以内で解けたかなと思ったが、1分18秒だった。
B - 180°
問題文を誤読するも、サンプルをちゃんと確かめて、reverseの必要性に気がつく。
s = gets.to_s.chomp puts s.tr('69', '96').reverse
競プロでは文字列を文字や数値の配列に変換した方が速いことが多いが、
この問題はシンプルで制約もキツくないので、あまり難しいことを考えずにすむ。
方針としては、6と9だけ、操作すると反転して入れ替わる。
1文字の置換(swap)は、trメソッドが便利なことが多い。
また、Rustは文字列の反転はないらしいが、Rubyは競プロ的に便利なことにある。
B問題の最短コードを見たが、yuruhiyaさんやkotatsugameさんのbashのコードが最短だった。
tr 69 96|rev
自分のRubyコードに似ている。 bashやzshのコマンドやスクリプトで、ちょっとしたことでいつか使えるかもしれない。
ここまでで、2m44s。悪くはない。
C - Made Up
少し悩んだ。AとBCが独立で、それぞれ同じ種類となるペアを求める。
制約的に二重ループを回せばTLEになる。
コンテストの時のことはちゃんと覚えてないが、それぞれの同じ数になるものの個数を求めておいて、かけ合わせれば良さそう。
数を数えるときはtallyメソッドが便利。
n = gets.to_s.to_i
a = gets.to_s.split.map{ |e| e.to_i }
b = gets.to_s.split.map{ |e| e.to_i }
c = gets.to_s.split.map{ |e| e.to_i - 1 }
t1 = a.tally
t2 = c.map{ |j| b[j] }.tally
ans = 0
(1..n).each do |k|
ans += (t1[k] || 0) * (t2[k] || 0)
end
puts ans
なお、他の人の解答を見てると、片方のみをtallyメソッドで数えて、もう片方はeachで回して合計をしている方が多そうだった。
ここまでで、7m51s。特別悪いというわけではないが、速い方はもっと速いので、速くしたい。
D - aab aba baa
問題文を読んで、ABC161のD - Lunlun Numberを思い出して調べる。
しかし、Lunlun Numberは、K≦100,000のK番目を求める問題で、Kの制約が小さく順番に下から数え上げられるが、
この問題は制約が大きくて、下から順番に数え上げていくことはできない。
なんとなくこういう問題は、左から決めていく。
使える文字がaかbか片方のみだったら、1種類しか作れないので、それを答える。
なお、最初から使える文字が片方だったら、1種類しか作れないので、1番目を聞かれるはず。
最初に使える文字が、aもbも両方の可能性があるとする。二択である。aとすると、残りのパターンは、二項係数(a - 1 + b)C (a - 1)となる。もし、この場合の数がちょうどkだった場合は、 aを最初にもってきた上、次にbを全て優先させた並びが答えとなる。もし、この(a - 1 + b)C (a - 1)がk以上であれば、最初にaを持ってくるパターンの中に答えがあることになるので、aの可能性を1減らした上で、次の文字を考える。同様に、この(a - 1 + b)C (a - 1)がk未満であれば、aのパターンの中に答えはないので、bから始まるパターンが答えとなり、bを答えに保存した上で、bの残数を1減らす。
class Integer def nCk(k) n = self return 0 if k < 0 || n < k ret = 1/1r k = [k, n - k].min k.times do ret = ret * n / k n -= 1 k -= 1 end ret.to_i end end a, b, k = gets.to_s.split.map{ |e| e.to_i } ans = "" (a + b).times do |i| if a == 0 || b == 0 puts ans + 'a' * a + 'b' * b exit end t = (a - 1 + b).nCk(a - 1) if t == k puts ans + 'a' + 'b' * b + 'a' * (a - 1) exit elsif t > k ans << 'a' a -= 1 else ans << 'b' b -= 1 k -= t end end puts ans + 'a' * a + 'b' * b
この問題は、二項係数の選ぶ数が30以下にしかならないので、愚直に計算して答えを求める。
Rubyは多倍長整数が使えるし、この程度であれば工夫は不要。
ここまでで29m12s。ちょっと時間がかかりすぎてしまった。
E - Count Descendants
考えても解けなかった。悔しい。この気持ちを大切にしたい。
木グラフ(Treeグラフ)で、DFSでオイラーツアーを使う問題。 他にも色々とやり方があるようだが。
行きがけ・帰りがけで記録したらできそうと思ったが、帰りの経路を覚えておく方法がわからなかった。
勉強不足でオイラーツアーという言葉もでてこなかった。
qib-sanのコードが、公式解説と同じやり方のようで、とても参考になった。
以下は、qib-sanのコードを自分風に書き換えたもの。
n = gets.to_s.to_i
parents = gets.chomp.split.map {|v| v.to_i - 1 }
g = Array.new(n) { [] }
parents.each.with_index(1){ |parent, child| g[parent] << child }
src = 0
st = [~ src, src]
depthes = Array.new(n) { [] }
dist = Array.new(n, -1)
dist[src] = 0
t_in = Array.new(n)
t_out = Array.new(n)
t = 0
while (cur = st.pop)
if cur >= 0
t_in[cur] = t
depthes[dist[cur]] << t_in[cur]
g[cur].each do |v|
next if dist[v] >= 0
dist[v] = dist[cur] + 1
st << ~ v
st << v
end
else
t_out[~ cur] = t
end
t += 1
end
# p depthes # [[0], [1, 3], [4, 6, 8], [9], [], [], []]
# p t_in # [0, 3, 1, 8, 6, 9, 4]
# p t_out # [13, 12, 2, 11, 7, 10, 5]
# depthes[2] # [4, 6, 8]
# p depthes[2].bsearch_index {|t| t >= t_in[0] } # 0 -> m - 0 => 3
# p depthes[2].bsearch_index {|t| t >= t_out[0] } # nil -> m - m => 0
q = gets.to_s.to_i
q.times do
u, d = gets.to_s.chomp.split.map(&:to_i)
u -= 1
m = depthes[d].size
ub = depthes[d].bsearch_index {|t| t >= t_in[u] } || m
lb = depthes[d].bsearch_index {|t| t >= t_out[u] } || m
puts lb - ub
end
帰りの経路を調べるためには、「帰りの頂点はここを調べるよ」とスタックに入れてあげる必要がある。
ここで、行きの経路として調べるために、行きは非負整数だったが、帰りは負数に対応させてあげる。
1対1対応で非負整数を負数に対応させるときは、~を使うと反転できていいらしい。
単に-でマイナスをすると、-0は0なので0と区別がつかない。
p [*0..3].map{ |e| -e } #=> [0, -1, -2, -3] p [*0..3].map{ |e| ~e } #=> [-1, -2, -3, -4]
詳しい解法については公式解説を読むとよさそうです。
RubyのArrayのunshiftはpushと比べて同じだったり遅かったりする
最初に
自分の整理のためにRubyのArrayのpushとunshiftの速さについて書く。
結論からいうと、Array#unshiftは、pushと同じ並の速さをだすこともあれば、格段に遅くなることもある。
他の言語だと遅いが、RubyのArray#unshiftは速い
C++のvectorにはpush_backとpop_backという末尾への追加と取り出しはあるが、
先頭への追加・取り出しのpush_frontとpop_frontはない。
これはC++のvectorが、末尾への追加・取り出しは高速にできるが、先頭への追加・取り出しは容易にできないデータ構造だから、実装されてないと考えられる。
これは、他の言語でも似たようなことが言えて、JavaScriptやPythonでの基本的な配列(≒リスト)では先頭への追加・取り出しと末尾への追加・取り出しの両方が用意されているのが、後者が明らかに遅いようだ。
しかし、Rubyの末尾追加であるArray#unshiftは、必ずしも遅いわけではない。(遅いケースもあるのだが)
2019/07 RubyのArray#unshiftが速すぎる件と償却解析
実際、こういった記事を読んだり、経験などから、
Rubyの末尾追加であるArray#unshift (prepend)は、Array#push (append)と同等のスピードである、と感じていた。
すごく単純な時間計測をするとunshiftとpushを比べてみると、同等のスピードであることがわかる。
require 'benchmark' n = 10**5 Benchmark.bm(10) do |r| r.report("empty-loop"){ |i| a = []; n.times{ } } r.report("push "){ |i| a = []; n.times{ a.push(0) } } r.report("unshift "){ |i| a = []; n.times{ a.unshift(0) } } end # user system total real # empty-loop 0.002462 0.000000 0.002462 ( 0.002460) # push 0.005110 0.000000 0.005110 ( 0.005112) # unshift 0.005339 0.000000 0.005339 ( 0.005341)
上記の例では、10**5(100,000)個の要素を追加するのに、末尾追加でも先頭追加でも0.005秒かかっている。
同じループ数で空のループが0.0025秒で、pushでもunshiftでもO(1)の時間計算量であるといえそう。
ところで、ここで思うのは、単純な比較だが、要素を追加していく処理とループ処理がザックリ0.0025秒ほどで、 ループ処理は意外にけっこう重たい処理なように感じる。
こういうわけで、自分はpushとunshiftは常にO(1)の時間計算量であると思っていた。(これは誤りであった。)
RubyのArrayのunshiftは、やっぱり遅い一面がある。
競技プログラミングの「競プロ典型 90 問」の44問目の問題を解いて、unshiftは常に速いとは限らないことがわかった。
下記の例では、a[0] = 0という破壊的操作を加えた上に、同じように10**5個の要素を追加している。
しかし、明らかにunshiftが遅い。
require 'benchmark' n = 10**5 Benchmark.bm(8) do |r| r.report("= & push "){ |i| a = []; n.times{ a[0] = 0; a.unshift(0) } } r.report("= & unshift "){ |i| a = []; n.times{ a[0] = 0; a.push(0) } } end # user system total real # = & push 0.006590 0.000000 0.006590 ( 0.006592) # = & unshift 2.215506 0.000655 2.216161 ( 2.216260)
pushの方が0.0065秒、unshiftの方が2.2秒。
単純な比較ではpushとunshiftは同等の速さであったが、
a[0] = 0と破壊的操作を1つ加えるだけでunshiftが100倍以上も遅い結果となった。
pushは常にO(1)のようだが、unshiftは破壊的操作が加わると計算量がO(n)とかに変わるようでかなり遅くなっている。
最後に
Array#unshiftは、pushと同じ並のO(1)の速さをだすこともあれば、異常に遅い速さになることもなることがわかった。
気軽にunshiftを使うときは、破壊的操作をしてないか、遅くなってないかに気を配る必要がありそうだ。
最後になりますが、ruby-jpやTwitterで、mameさん、climpetさん、kuma kumaさん、tompngさん、superrino130さん等から、アドバイスや意見を貰え、とても参考になり感謝してます。
参考リンク
RubyでABC201(マイナビプログラミングコンテスト2021)のE問題までの解説
最初に
今週あたりは夜9時あたりに寝てたが、
頑張ってAtCoderのABC201ABC201(マイナビプログラミングコンテスト2021)に参加した。
コンテスト中はD問題まで解けて、E問題までACできたので、E問題まで簡単に参加記ないし解説を駆け足で書いていく。
A - Tiny Arithmetic Sequence
a = gets.to_s.split.map{ |e| e.to_i }.sort
puts (a[2] - a[1] == a[1] - a[0]) ? "Yes" : "No"
タブを開きすぎててコンテストに支障がありそうだったから、タブを削除。
ちょっと出遅れたけど、それでも2分ほどで解けたので悪くない。
Rubyにしては入力が冗長なのは、Crystalに移植しやすいようにしている。
そして、入力とともにソート。
昇順でも降順でもソートした数列の差が等しいかを見るだけ。
B - Do you know the second highest mountain?
A問題は数が3つだけで、数値だけのソートで良かった。
B問題は高さを指定して、ソートすると楽。
Rubyではこういうブロックを使うとき、sortではなく、sort_byを使う。
ちゃんと高さをto_iで数値変換した上でsort_byで比較しておかないと、文字列で比較してWAになってしまう。
n = gets.to_s.to_i m = Array.new(n){ gets.to_s.split }.sort_by{ |name, h| h.to_i } puts m[-2][0]
to_iを付け忘れる凡ミスで1WAとしてしまい、もったいない。
C - Secret Number
最初に場合分けを考えていたがすごく大変そうでミスしやすそうな解法で、ミスしない自信もなく書くのが大変そうで紙で数式を書いたりしながら考えいた。
考えていたところ、数が全体的に小さいから、全探索などで行けそうだとひらめいた。
s = gets.to_s.chomp o = s.count("o") q = s.count("?") a = ((1..o).to_a + (-q..-1).to_a).repeated_permutation(4).to_a p a.count{ |d| (1..o).all?{ |e| d.include?(e) } }
これはコンテスト後に、整理して通したコード。
xは使わないので除外して、oと?だけに集中して考えると見通しが良い。
何の数字がoやqになっているかは重要ではなく、oや?の種類の数が重要。
まず、String#countで、数を数える。oと?の種類数をoとqという変数に置いた。
(1..o).to_aと(-q..-1).to_aで、それぞれoを1からoまでの数、qを-qから-1までの数として適当に置き直した。
ここで、oと?をそれぞれ正の数と負の数に置き換えたが、元が異なる数字なので、重複しないことが重要。
そのあと、Array#repeated_permutationで4を指定して、oと?の数字を使った4文字の暗号を全探索するために全て列挙する。
配列aには、可能性のある全ての暗号が入っている。※最初から可能性のないxは除いている。
この可能性のある暗号の中で、条件に当てはまるものだけをcountで数えていく。
条件にあてはまるかどうかは、all?でoの数字が全てつかわれているかを見る。
D - Game in Momotetsu World
こういう感じの必勝法を考えるときは、ゴールから逆算して後ろから考える。
2人で交互に1から3個の連続した数値をいっていって最初に21を言った方が負け、みたいなゲームの必勝法を考えるときも、後ろから考える。
「もしここからスタートしてたらいくつの点差になるか」をゴールから逆算して後ろから考える。
考えながらも雰囲気で解いた感じのところがあるので、嘘解法でない自信がちょっとないが、簡単に解説を書いていく。
右か下に動いていくので、必ず1番右の部分で終わる。ここがゴール。
そして、高橋君と青木君が交互に動かすが、どちらに影響するマスかは市松模様となることがわかる。
i + jの偶奇でわかれる市松模様で、プラスマイナスは逆の意味になる。
つまり、青木君にとっての+-は、高橋君にとっての-+になる。
i + jの偶奇で+-を反転させるとよさそう。
また、+-がポイントに与える影響を考えると、+1, -1となる。
Rubyでは、文字の配列を作ると重たくなることがあり、今回は要素数が多かったので、String#bytesですぐ数値の配列を作りにいっている。
また、^が排他的論理和(xor)の演算子であり、これを使うと1と-1の振り分けが容易になる。
なお、String#bytesは、バイトの数値(ここでは文字コードと同じ)に変換するメソッドで、'+'は43, '-'は45に変換される。
自分の実装だと、1行か1列のとき、つまりH == 1 || W == 1のときにコーナーケースとなるようなので、別で実装した。
サンプルにH == 1 && W == 1のケースを置いてくれてありがたい。
H == 1 && W == 1のときは、最初の高橋君が動かせずポイントが変わらないので、"Draw"を出力して即終了。
また、W == 1のときは、transposeで二重配列の縦横を入れ替える等して、H == 1としてまとめて処理するようにした。
先に、1番後ろの列と行から始めるケースだと、両者選択の余地がないので、単純に後ろから累積和を作る要領で、その地点から始めたときのポイント差を求めた。
そして、それ以外のケースでは、高橋君が動かすときは右と下でポイント差を最大化できる方に動くのでmaxメソッドで判定して大きい方を取り、反対に青木君だとポイント差が逆のマイナス方向に動くようにminメソッドで判定して小さい方を取る形で、累積和を求めるようなDPをした。
$debug = false h, w = gets.to_s.split.map{ |e| e.to_i } if h == 1 && w == 1 puts "Draw" exit end m = Array.new(h){ |i| gets.to_s.chomp.bytes.map.with_index{ |e, j| ((i + j).even? ^ (e == 43)) ? 1 : -1 } } if h == 1 || w == 1 m = m.transpose if w == 1 w = [w, h].max h = 1 end (w - 1).downto(1){ |j| m[-1][j - 1] += m[-1][j] } (h - 1).downto(1){ |i| m[i - 1][-1] += m[i][-1] } if h == 1 puts ["Draw", "Takahashi", "Aoki"][m[0][1] <=> 0] exit end puts m.map{ _1.join(" ") } if $debug (h-2).downto(0) do |i| (w-2).downto(0) do |j| if (i + j).even? m[i][j] += [m[i + 1][j], m[i][j + 1]].max else m[i][j] += [m[i + 1][j], m[i][j + 1]].min end end end puts m.map{ _1.join(" ") } if $debug mm = [m[0][1], m[1][0]].max puts ["Draw", "Takahashi", "Aoki"][mm <=> 0]
puts ["Draw", "Takahashi", "Aoki"][m[0][1] <=> 0]
出力のこの部分は、普段はこのように自分は書かないけど、本質に関係ない部分を短くするため、書き直した。
<=>は大小判定で-1, 0, 1を返すメソッドで、配列に3要素のどれかを取る形になる。
実際は、サンプル1で、書きながら考えた。
| 0 | 1 | 2 |
|---|---|---|
| T | A | |
| T | A | T |
| A | T | A |
↓
+1だと高橋君に有利なようにポイントが大きくなる。
| 0 | 1 | 2 |
|---|---|---|
| -1 | +1 | |
| +1 | +1 | +1 |
| +1 | -1 | +1 |
↓
| 0 | 1 | 2 |
|---|---|---|
| 2 | 3 | |
| -1 | 2 | 2 |
| -1 | 0 | 1 |
右下から累積和をとっていく。この表が作れるように頑張る。
(考え方は正しいと思うが、ちょっとやっぱりミスってる気がしてる気が。コーナーケースができるのが変な気がする)
E - Xor Distances
木の問題に苦手意識があって飛ばしてF問題を最初に考えてたが、こっちを頑張った方が良さそうだった。
こっちは、典型問題や過去問の組み合わせで解けるような感じだった。
ある頂点から全ての頂点に対するxorのdistを求める。要素数Nのxorのdistという距離が入った配列を作る。
これは木のBFSやDFSといった典型のやり方で距離を求めるところを、+から^に変えて、xor距離なるものを求めるようにする。
そうすると、xorの二重和というABC147のD - Xor Sum 4という問題に帰着できる。ここ、論理が少し飛躍してるかも。
mod = 10**9 + 7 n = gets.to_s.to_i g = Array.new(n){ [] } (n - 1).times do s, t, w = gets.to_s.split.map{ |t| t.to_i } s -= 1 t -= 1 g[s] << [t, w] g[t] << [s, w] end d = [-1] * n s = 0 d[s] = 0 q = [s] while ( v = q.pop ) t = d[v] g[v].each do |(u, c)| next if d[u] >= 0 d[u] = t ^ c q << u end end # ここで、zero based originで0番目の頂点からのxor距離が d に入った。 # ABC147 D - Xor Sum 4 ans = (0..60).sum do |i| c = d.sum{ |k| k[i] } c * (n - c) << i end puts ans % mod
ABC147のD - Xor Sum 4に帰着できることは正しいので、最初にこの問題を解けるようになった方がいい。
ABC147のD - Xor Sum 4の解説は、けんちょんさんの解説がわかりやすかった。
最後に
駆け足で書きましたが、ABC201(マイナビプログラミングコンテスト2021)の解説でした。